
ML&PR_6: Entropy | 1.6.
-
date_range 19/06/2020 16:39 infosortMachine_Learning_n_Pattern_Recognitionlabelmlbishopstat
- In this blog, we will discuss about Information theory, about its concept and its mathematical nature.
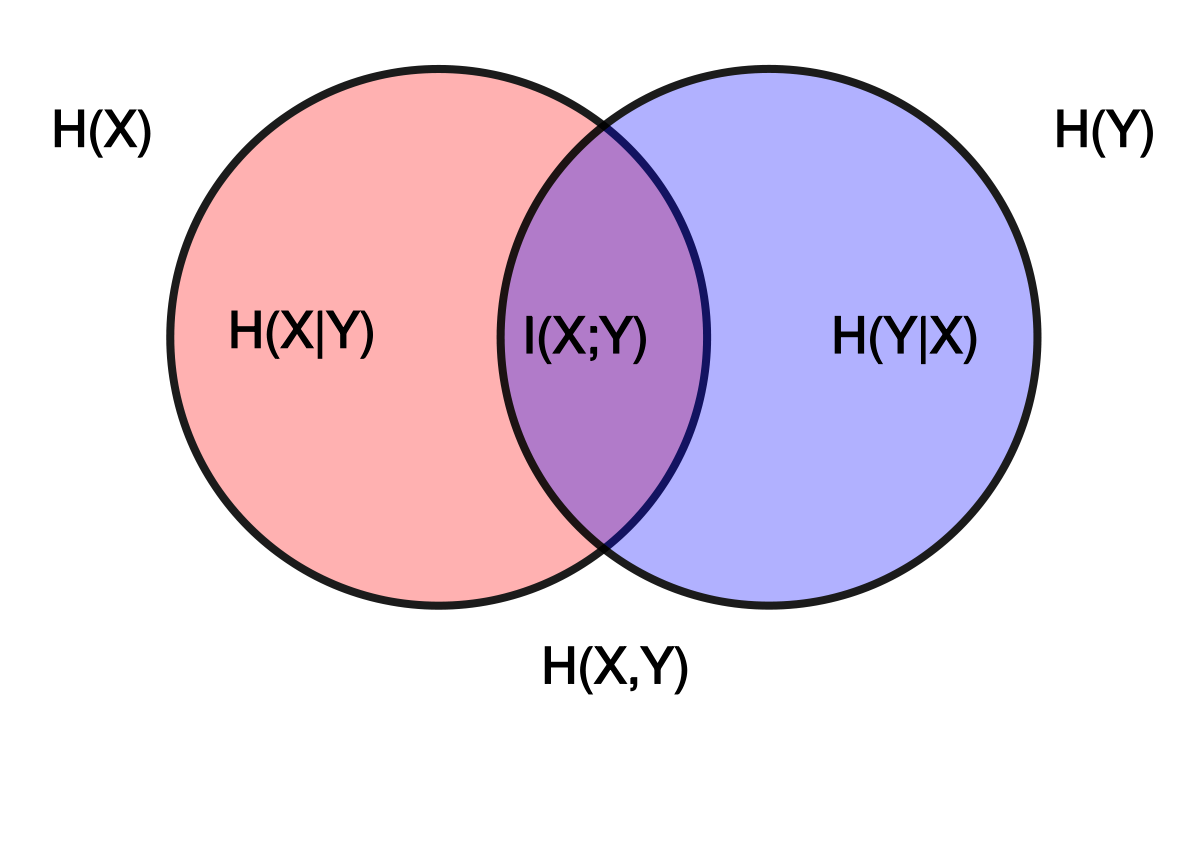
Table of content:
1. Entropy
Let consider a discrete random variable . We wonder how much information is received when we observe a specific value for this variable. The amount of information can be viewed as the degree of surprise of or the uncertainty of variables.
The intuition for entropy is that it is the average number of bits required to represent or transmit an event drawn from the probability distribution for the random variable.
We use a quantity as a measure for information content and the must be a monotonic function of the probability distribution .
If we have two events and that are unrelated, so . Cause and are independent, then . From two relationships, we can show that:
where the negative sign ensures that the value of is positive or zero.
The average amount of information of a random variable with distribution :
called the entropy of the random variable .
(A) We can see that, achieves the maximum when all of are equal.
In general, we have entropy of continuous variable:
2. Joint Entropy
- Joint entropy is a measure of the uncertainty associated with a set of variables. It is the entropy of a joint probability distribution. With two distributions, it is defined by:
3. Condition entropy
Consider a joint distribution . If a value of is already known, the average additional information needed to specify can be written as:
In other hand, we can write:
Thus, we have:
4. Mutual information
Mutual information is a quantity that measures a relationship between two random variables that are sampled simultaneously. It is defined as:
We also have:
Mutual information is a symmetry function, so it can be used as a metric, that measures the same of two distribution.
5. Properties
. It is equal when where .
Similarity, joint entropy, condition entropy and mutual information are also positive or zero.
From , we have .
From , we have .
From and , we have and .
From and , we have .
Reference:
[5] Entropy and Mutual Information | University of Massachusetts Amherst.
[6] Cross-entropy for machine learning | Machine Learning Mastery.
[7] 1.6| Pattern Recognition and Machine Learning | C.M. Bishop.
[8] 2.8.1 | Machine Learning A Probabilistic Perspective | K.P. Murphy