
ML&PR_5: Gaussian Distribution | 2.3.
-
date_range 14/06/2020 09:52 infosortMachine_Learning_n_Pattern_Recognitionlabelmlbishopstat
2.3. The Gaussian Distribution
The Gaussian, also known as the normal distribution, is a widely used model for the distribution of continuous variables. For single variable , the Gaussian distribution can be written in the form:
where are the mean and the variance respectively.
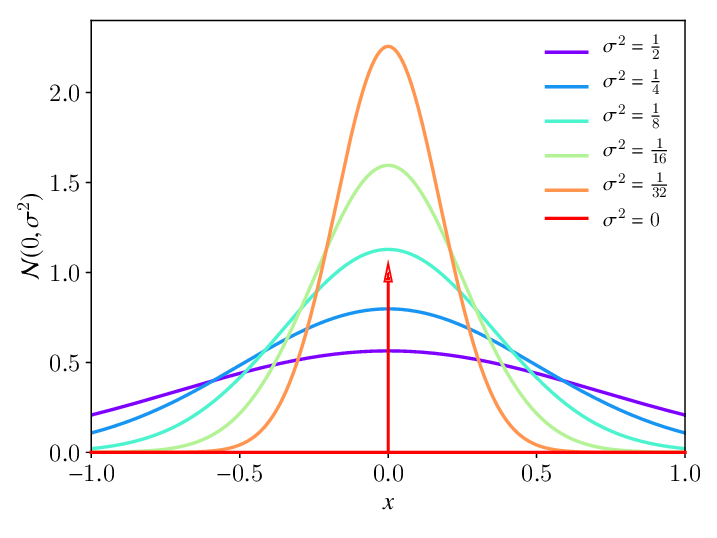
Figure 1: 1-dimensional Gaussian distribution Source: https://www.researchgate.net/figure/Gaussian-bell-function-normal-distribution-N-0-s-2-with-varying-variance-s-2-For_fig1_334535945 For dimensional vector , the multivariate Gaussian distribution takes the form:
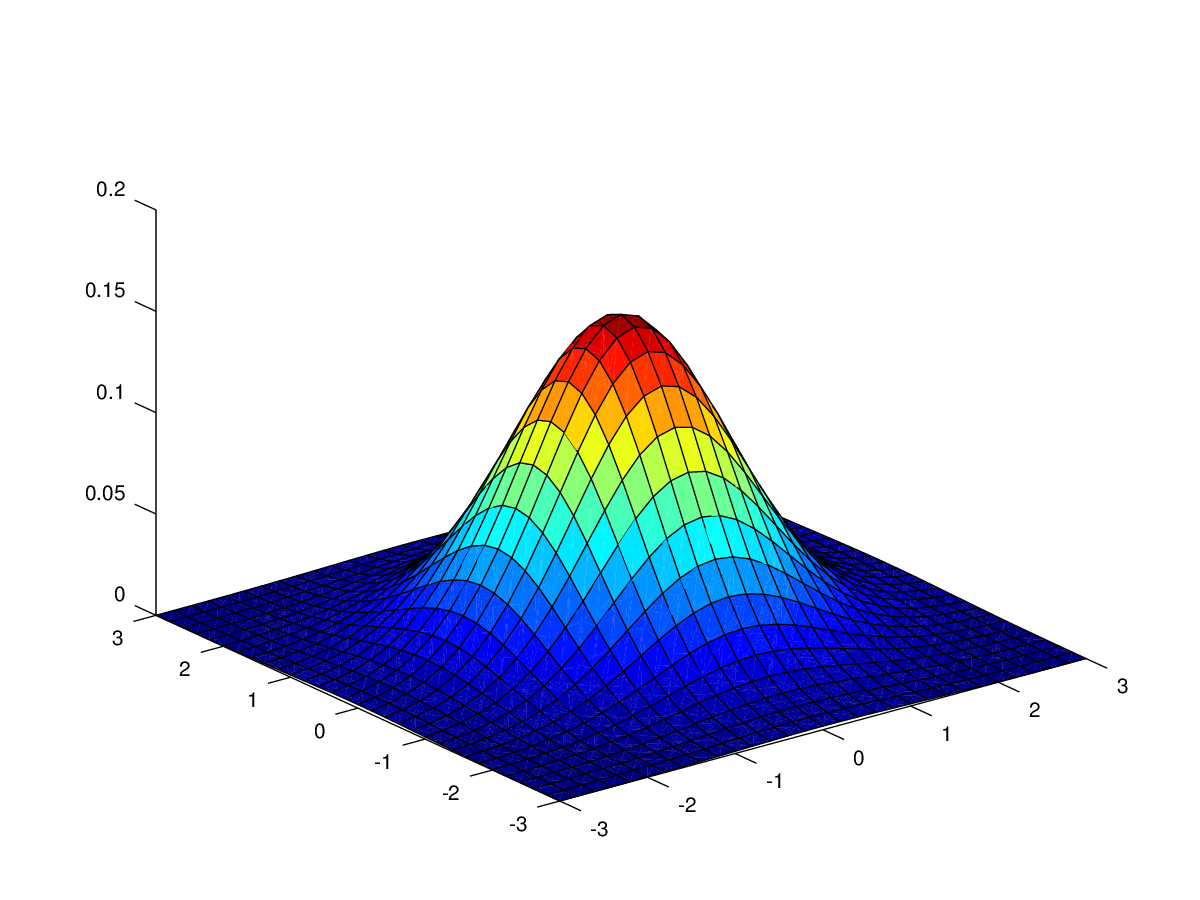
where the mean and the covariance matrix was mentioned in ML&PR_2.
The Gaussian distribution arises in many different context. For example, Figure 3 plots the mean of uniformly distributed numbers for various values of :
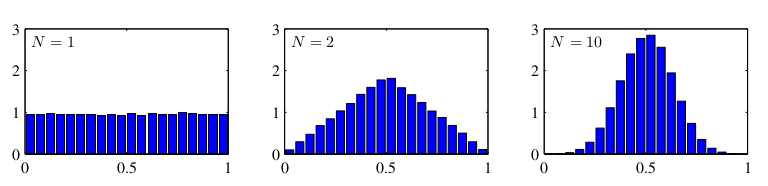
Figure 3 Source: Pattern Recognition and Machine Learning | C.M.Bishop Let consider the geometrical form of the Gaussian distribution:
The called Mahalanobis distance from to . In Euclidean distance, is identity matrix.
We know that is a symmetric matrix. So, it has only real eigenvalues, specifically eigenvalues :
where is a eigenvector corresponding to . The eigenvectors are chosen to form an orthogonal set such that:
We can rewrite in the form:
Similarity, we have:
From , becomes:
where .
because so .
Forming , we obtain:
Note that: is a orthogonal matrix.
If all of eigenvalues are positive, these surfaces represent ellipsoids with center and their axes oriented along . We see that is a vector projected into coordinate which scaling factor .
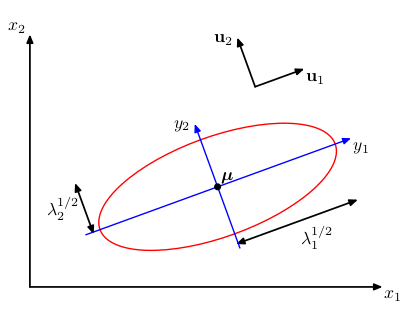
Figure 4 Source: Pattern Recognition and Machine Learning | C.M.Bishop Also, we have:
We now define
Then
Thus, in the coordinate system, the Gaussian distribution takes the form:
also
From we have:
where .
So:
where and .
We see that is an odd function, then .
From and , we have .
Therefore,
Let consider second order moments of the Gaussian - :
because is an odd function so the integral is equal zero.
We now consider:
We have because from we obtain:
because is an orthogonal matrix so .
because of .
We have from , have from .
because from we have
Thus
Appendix (*)
The product of the eigenvalues is the determinant of a matrix:
Proof:
First, we analysis to:
Use the property of determinant , we have:
The integral of Gaussian is 1:
We have to prove
Proof:
We now prove . We have:
Set , , we have:
So, we have just prove
Then, was proved.
Reference:
- 2.3 | Pattern Recognition and Machine Learning | C.M.Bishop.
- Gaussian integrals | University of Michigan.