
ML&PR_3: Binary Variables | 2.1.
-
date_range 05/05/2020 14:41 infosortMachine_Learning_n_Pattern_Recognitionlabelmlbishopstat
2.1. Binary variables
Let imagine when flip a coin, the outcome is 'heads' or 'tails'. We represent it by numerals representing 'heads' and representing 'tails'. Now we call is binary variable.
The probability of will be denoted by the parameter where :
and . The probability distribution of is a Bernoulli distribution:
And we have:
In general, when we flip a coin times and appears times. This is called Binomial distribution:
where
And:
2.1.1. Beta distribution
Suppose we have a observed data set . We have to determine so that is the largest. This is Maximum Likelihood method that we will refer later. You just need to know now:
If we just have a small data set, for instance , if we use formula , we have . Intuitively, we know that is not reasonable.
In order to fix this problem, we could choose a prior to be proportional and , then the posterior distribution, which is proportional to the product of the prior and likelihood function, will have same functional form as both the prior and likelihood. This property is called conjugacy. We choose a prior, called the Beta distribution:
where Gamma function has been introduced in MATH_4, just to make sure that:
The mean and variance of the Beta distribution:
The parameters and are called hyperparameters because they control the distribution of the .
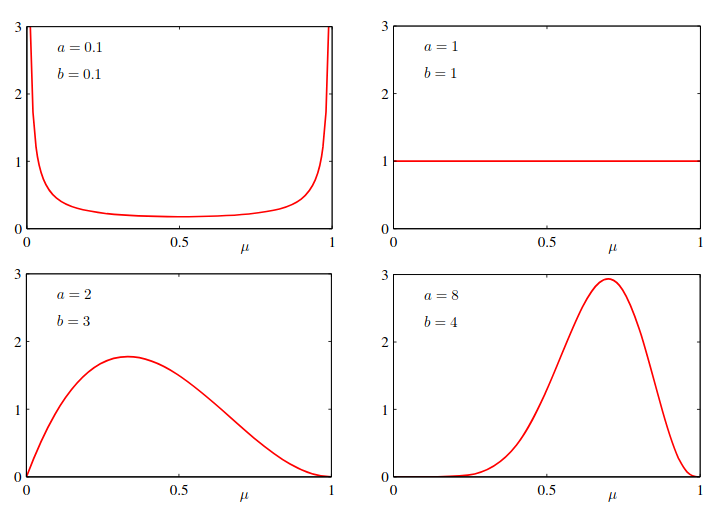
Figure 1 The posterior distribution of is now obtained by multiplying the beta prior by the binomial likelihood function and normalizing. Keep only the factors that depends on , we have:
where corresponds the number of 'tails'. Formula could normalize like a other beta distribution:
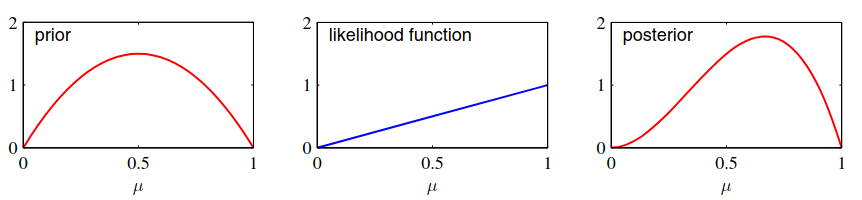
Figure 2 If we have a observes data set , using we obtain:
If , the result is approach to the maximum likelihood result .
In Figure 1, we see that as the number of observations increases, the posterior distribution becomes more sharply, because in formula , when or , the variance goes to zero. In other word, we observe more and more data, the uncertainty represented by the posterior distribution will decrease. To address this, we take a frequentist view, inference problem for parameter for which we have observed a data set , described by the joint distribution :
where
This result says that the posterior mean of , averaged over the distribution generating the data is equal to the prior mean of .
And we can show that:
Reference:
- 2.1 | Pattern Recognition and Machine Learning | C.M.Bishop.