
ML&PR_1: Đường cong phù hợp | 1.1.
-
date_range 04/04/2020 22:52 infosortMachine_Learning_n_Pattern_Recognitionlabelmlbishop
1.1. Đường cong phù hợp
Chúng ta bắt đầu bằng một ví dụ hồi quy đơn giản. Giả sử ta quan sát các dữ liệu với đầu vào và đầu ra là (, ).
- Ví dụ dữ liệu được sinh ra từ hàm () với giá trị đích () bị ảnh hưởng bởi nhiễu Gauss.
Cho tập huấn luyện quan sát được gồm mẫu , với x cùng với các giá trị , với t. Ví dụ với :
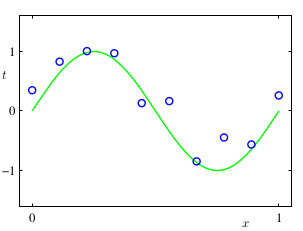
H1. Mục đích của chúng ta là tạo một hàm dự đoán giá trị từ một dữ liệu mới bằng cách khai thác tập dữ liệu huấn luyện. Điều này nghĩa là ta phải khám phá ra hàm từ một tập dữ liệu hữu hạn. Ở mặt tổng quát, mục tiêu của chúng ta là tìm một hàm số khái quát được dữ liệu thực từ dữ liệu huấn luyện. Đây là một nhiệm vụ thật sự khó. Hơn nữa, dữ liệu quan sát được đã bị ảnh hưởng bởi nhiễu.
Trong hoàn cảnh này, chúng ta có thể xem xét hướng tới một đường cong phù hợp với dữ liệu có thể quan sát:
với là bậc của đường cong, w=.
Hàm số phi tuyến với nhưng tuyến tính với w. Hàm số tuyến tính với các tham số chưa biết được gọi là mô hình tuyến tính (linear model).
Giá trị của các tham số w được xác định dựa trên tập dữ liệu huấn luyện (x,t) thông qua việc tối thiểu hàm lỗi - hàm đánh giá sai khác giữa nhãn và hàm dự đoán . Một hàm lỗi khá thông dụng là tổng bình phương lỗi của tất cả các điểm dữ liệu:
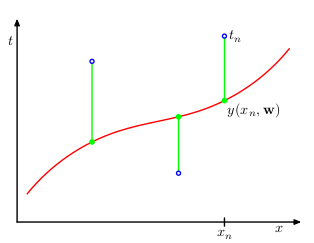
H2. Giá trị nhỏ nhất của hàm lỗi là khi đường cong đi qua tất cả điểm dữ liệu huấn luyện.
Do là hàm bậc của w nên tồn tại w* duy nhất sao cho hàm lỗi nhận giá trị nhỏ nhất. Khi đó đường cong sẽ là .
Câu hỏi kế tiếp là: bằng bao nhiêu là hợp lý?.
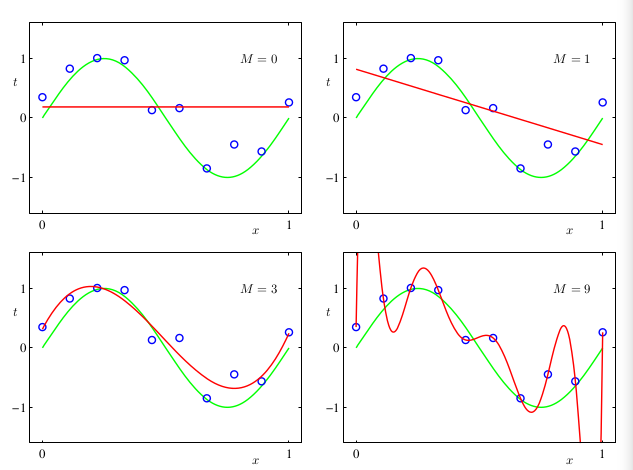
H3. Việc chọn bậc của hàm số được gọi là model comparison hay model selection. Với ví dụ trên, ta có đưa ra vài nhận xét:
- Hai đường cong với và đều không phù hợp với dữ liệu, không thể đại diện cho hàm ().
- Bằng trực giác, có vẻ là lựa chọn hợp lý nhất.
- Đường cong cuối cùng đi qua tất cả các điểm dữ liệu, . Hàm số này có giá trị hàm lỗi lý tưởng nhưng lại không thể đại diện cho hàm (), không biểu diễn được đặc trưng của dữ liệu. Trường hợp này gọi là overfitting.
Như đã đề cập ở trên, mục đích của chúng ta là tạo ra hàm dự đoán cho những dữ liệu không biết trước. Vì vậy, sau khi hàm được học từ tập dữ liệu huấn luyện, chúng ta đánh giá hàm số này như sau:
Sinh ra dữ liệu từ hàm () với nhiễu Gauss (như đã đề cập ở đầu bài viết).
Sau đó dùng hàm lỗi để đánh giá. Đôi khi để thuận tiện, người ta có thể dùng hàm lỗi Root mean square (RMS):
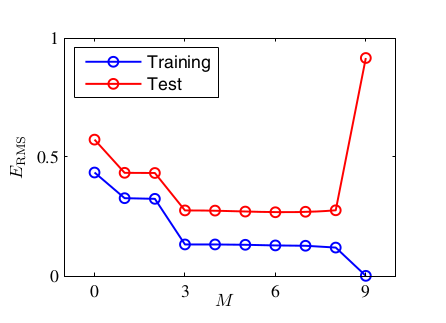
H4.
Tiếp theo, hãy xem xét bảng sau:

H5. Thấy rằng, khi càng lớn thì giá trị của w* cũng lớn theo. Điều này nghĩa là, với tham số càng lớn thì hàm số càng dễ bắt được chính xác các điểm dữ liệu huấn luyện (như H3.). Mặt khác, tham số lớn khiến hàm số quá linh hoạt, quá tập trung vào dữ liệu, khiến cho nó quá nhạy cảm với nhiễu, dẫn đến việc dự đoán các dữ liệu ngoài tập huấn luyện không có kết quả tốt.
Ví dụ tiếp, vẫn với :
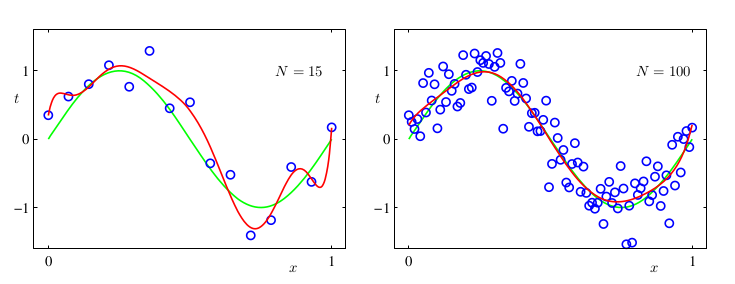
H6. M=9 Dễ thấy rằng, overfitting khó xảy ra khi tập dữ liệu huấn luyện lớn. Nói cách khác, khi dữ liệu lớn, ta có thể tìm ra hàm số phù hợp với dữ liệu dù có lớn.
Một mô hình có quá linh hoạt (nhiều tham số) phải cần nhiều dữ liệu để tránh overfitting. Bây giờ cùng xem xét: Làm thế nào để tìm ra mô hình phù hợp khi lượng dữ liệu nhỏ cho hàm số phức tạp ( lớn)? Trong trường hợp này, một kỹ thuật để tránh overfitting được gọi là regularization. Kỹ thuật này hạn chế các hệ số w quá lớn bằng cách cộng nó vào cùng với hàm lỗi :
với (lưu ý rằng công thức trên không có ), hệ số ví như là "tầm quan trọng" giữa regularization và tổng bình phương lỗi. Nghĩa là, khi càng lớn thì việc tối thiểu hóa sẽ tập trung vào việc tối thiểu nhiều hơn và ngược lại.
Khi tối thiểu , ngoài việc tối thiểu sai số giữa dự đoán và thực tế, giá trị của w không được phép quá lớn khiến cho mô hình không quá tập trung vào dữ liệu. Đây là lý do không có trong do không tương tác với dữ liệu (xem công thức ). Kết quả của kỹ thuật regularization với và :
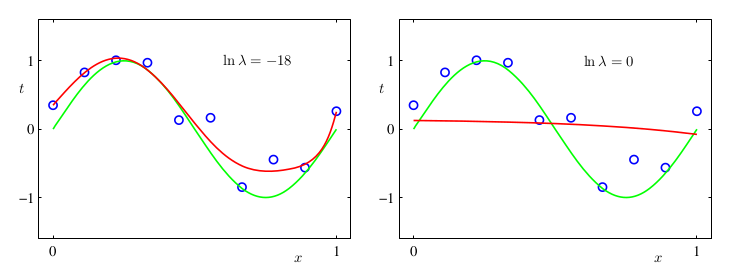
H7. 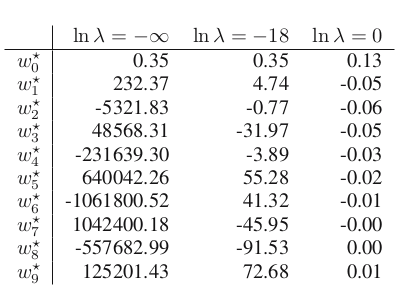
H8. Ảnh hưởng của lên độ phức tạp của mô hình:
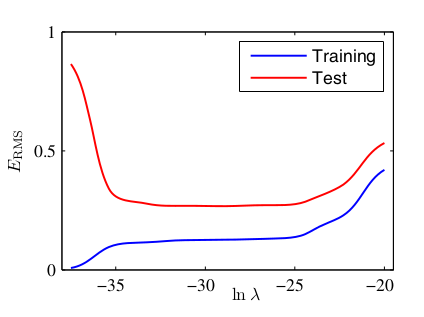
H9. Dựa vào H7. và H9., có thể thấy, càng lớn khiến mô hình càng đơn giản. Ngược lại, quá nhỏ khiến regularization gần như không có tác dụng.
- Như vậy là bài viết này đã cung cấp cho bạn đọc ý tưởng, các kỹ thuật tìm một hàm số phù hợp với dữ liệu cho trước.
Tham khảo:
- Mục 1.1 | Pattern Recognition and Machine Learning | C.M.Bishop