
UML_2: Tối thiểu rủi ro thực nghiệm | 2.2.
-
date_range 03/04/2020 15:25 infosortStatistical_Learninglabelslvapnik
2.2. Tối thiểu rủi ro thực nghiệm
- Như đã đề cập ở phần trước, một thuật toán học có đầu vào là tập huấn luyện được lấy mẫu bởi phân bố không biết trước và được gán nhãn bằng hàm . Đầu ra của thuật toán học là hàm dự đoán . Mục đích của thuật toán là tìm hàm với sai số trên là nhỏ nhất.
- Tuy nhiên, và không biết trước nên ta không thể tìm được lỗi thật (true error, lỗi trên ) của bộ học mà chỉ có thể tính được lỗi trên tập huấn luyện (lỗi trên ):
với .
- Ở góc nhìn khác, hàm lỗi thể hiện xác suất đoán đúng của hàm dự đoán. Lỗi này được gọi là sai số thực nghiệm (empirical error). Vì vậy, nếu bộ dữ liệu huấn luyện đại diện cho dữ liệu "thật" (dữ liệu trên ), ta có thể tối thiểu với hi vọng cũng được tối thiểu - được gọi là "Tối thiểu rủi ro thực nghiệm" (Empirical Risk Minimization) hay ERM.
2.2.1. Overfitting
- Phương pháp ERM có thể dẫn đến một kết quả tồi. Trước tiên hãy xem xét ví dụ sau:
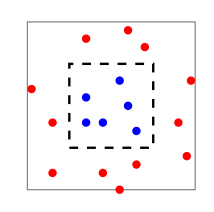
- Một bộ học muốn dự đoán trái đu đủ đã chín hay chưa dựa vào độ mềm và màu sắc. Giả sử với là phân phối đều và hàm gán nhãn là hình vuông nét đứt, với các điểm bên trong được gán nhãn và với các điểm bên ngoài. Diện tích hình vuông lớn là , hình vuông nhỏ là . Xem xét hàm dự đoán sau:
- Hàm dự đoán trên có vẻ "thông minh" khi với rủi ro thực nghiệm . Tuy nhiên, mục đích cuối cùng của việc học vẫn là tối thiểu chứ không phải . Trong trường hợp này, hàm dự đoán cho kết quả đúng với các điểm đã biết ( với ) và các điểm có nhãn (các điểm ngoài hình vuông nhỏ; với những điểm không thuộc tập dữ liệu). Do đó, .
- Hàm dự đoán trên là một ví dụ về overfitting, khi mà bộ học học tốt trên dữ liệu huấn luyện nhưng có hiệu suất kém trên dữ liệu thực.